IT就到黑馬程序員.gif "學(xué)IT就到黑馬程序員")
K-近鄰算法
什么是k-近鄰算法��?就是根據(jù)你的鄰居推斷出你的類別
概念:
K Nearest Neighbor算法又叫KNN算法���,這個(gè)算法是機(jī)器學(xué)習(xí)里面一個(gè)比較經(jīng)典的算法, 總體來說KNN算法是相對(duì)比較容易理解的算法
定義
如果一個(gè)樣本在特征空間中的k個(gè)最相似(即特征空間中最鄰近)的樣本中的大多數(shù)屬于某一個(gè)類別�����,則該樣本也屬于這個(gè)類別�����。
來源:KNN算法最早是由Cover和Hart提出的一種分類算法
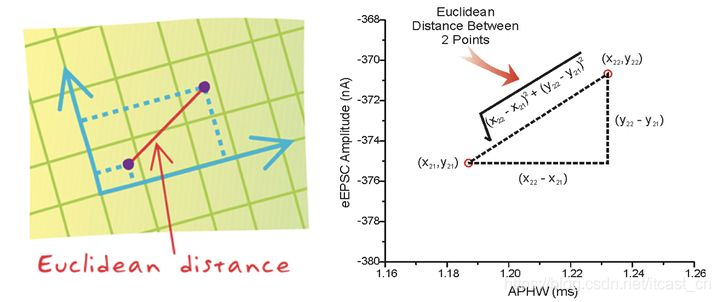
距離公式
兩個(gè)樣本的距離可以通過如下公式計(jì)算�����,又叫歐式距離 ����,關(guān)于距離公式會(huì)在后面進(jìn)行討論
線性回歸
應(yīng)用場(chǎng)景為:房?jī)r(jià)預(yù)測(cè)、銷售額度預(yù)測(cè)���、貸款額度預(yù)測(cè)
什么是線性回歸��?
(1)定義與公式
線性回歸(Linear regression)是利用回歸方程(函數(shù))對(duì)一個(gè)或多個(gè)自變量(特征值)和因變量(目標(biāo)值)之間關(guān)系進(jìn)行建模的一種分析方式��。
特點(diǎn):只有一個(gè)自變量的情況稱為單變量回歸��,多于一個(gè)自變量情況的叫做多元回歸��。

線性回歸用矩陣表示舉例:
那么怎么理解呢�?我們來看幾個(gè)例子
期末成績(jī):0.7×考試成績(jī)+0.3×平時(shí)成績(jī)
房子價(jià)格 = 0.02×中心區(qū)域的距離 + 0.04×城市一氧化氮濃度 + (-0.12×自住房平均房?jī)r(jià)) + 0.254×城鎮(zhèn)犯罪率
上面兩個(gè)例子����,我們看到特征值與目標(biāo)值之間建立了一個(gè)關(guān)系,這個(gè)關(guān)系可以理解為線性模型����。
邏輯回歸
邏輯回歸(Logistic Regression)是機(jī)器學(xué)習(xí)中的一種分類模型,邏輯回歸是一種分類算法����,雖然名字中帶有回歸�����。由于算法的簡(jiǎn)單和高效����,在實(shí)際中應(yīng)用非常廣泛��。
應(yīng)用場(chǎng)景:廣告點(diǎn)擊率�����、是否為垃圾郵件��、是否患病��、金融詐騙����,虛假賬號(hào)。
這里就可以發(fā)現(xiàn)一個(gè)特點(diǎn)了���,就是兩個(gè)類別之間都屬于判斷�����,邏輯回歸就是解決二分類問題的利器�。
要想掌握邏輯回歸�,必須掌握兩點(diǎn):
邏輯回歸中,其輸入值是什么
如何判斷邏輯回歸的輸出
輸入:
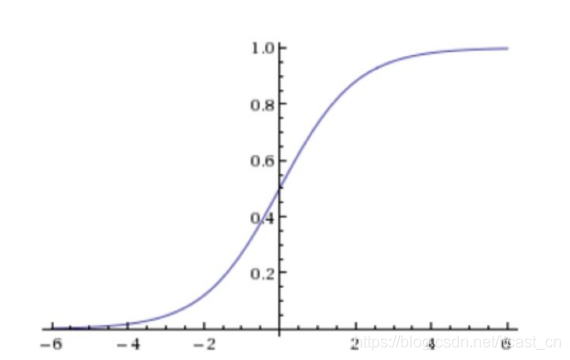
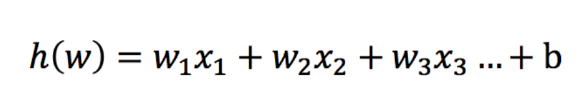 激活函數(shù):sigmoid函數(shù)
激活函數(shù):sigmoid函數(shù)
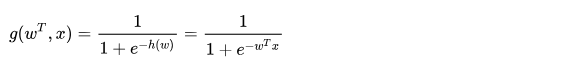
判斷標(biāo)準(zhǔn)
回歸的結(jié)果輸入到sigmoid函數(shù)當(dāng)中
輸出結(jié)果:[0, 1]區(qū)間中的一個(gè)概率值�,默認(rèn)為0.5為閾值
邏輯回歸最終的分類是通過屬于某個(gè)類別的概率值來判斷是否屬于某個(gè)類別,并且這個(gè)類別默認(rèn)標(biāo)記為1(正例),另外的一個(gè)類別會(huì)標(biāo)記為0(反例)��。(方便損失計(jì)算)
輸出結(jié)果解釋(重要):假設(shè)有兩個(gè)類別A�����,B�����,并且假設(shè)我們的概率值為屬于A(1)這個(gè)類別的概率值?�,F(xiàn)在有一個(gè)樣本的輸入到邏輯回歸輸出結(jié)果0.55�,那么這個(gè)概率值超過0.5,意味著我們訓(xùn)練或者預(yù)測(cè)的結(jié)果就是A(1)類別��。那么反之�,如果得出結(jié)果為0.3那么���,訓(xùn)練或者預(yù)測(cè)結(jié)果就為B(0)類別。
關(guān)于邏輯回歸的閾值是可以進(jìn)行改變的��,比如上面舉例中�,如果你把閾值設(shè)置為0.6,那么輸出的結(jié)果0.55���,就屬于B類����。
決策樹算法
決策樹思想的來源非常樸素�����,程序設(shè)計(jì)中的條件分支結(jié)構(gòu)就是if-else結(jié)構(gòu)����,最早的決策樹就是利用這類結(jié)構(gòu)分割數(shù)據(jù)的一種分類學(xué)習(xí)方法
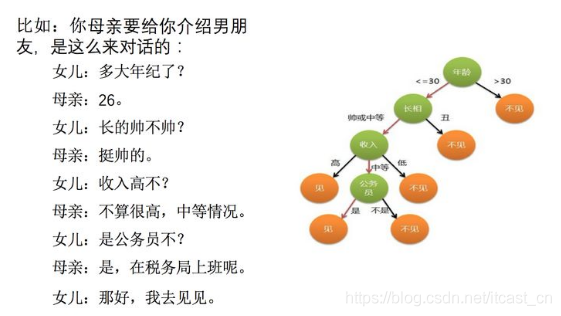
決策樹:是一種樹形結(jié)構(gòu),其中每個(gè)內(nèi)部節(jié)點(diǎn)表示一個(gè)屬性上的判斷���,每個(gè)分支代表一個(gè)判斷結(jié)果的輸出�,最后每個(gè)葉節(jié)點(diǎn)代表一種分類結(jié)果,本質(zhì)是一顆由多個(gè)判斷節(jié)點(diǎn)組成的樹�。
怎么理解這句話?通過一個(gè)對(duì)話例子
上面案例是女生通過定性的主觀意識(shí)���,把年齡放到最上面���,那么如果需要對(duì)這一過程進(jìn)行量化�,該如何處理呢?
此時(shí)需要用到信息論中的知識(shí):信息熵��,信息增益�����。
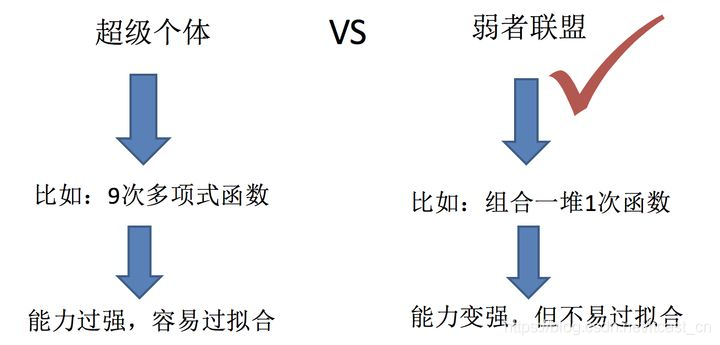
集成算法
集成學(xué)習(xí)通過建立幾個(gè)模型來解決單一預(yù)測(cè)問題��。它的工作原理是生成多個(gè)分類器/模型�,各自獨(dú)立地學(xué)習(xí)和作出預(yù)測(cè)。這些預(yù)測(cè)最后結(jié)合成組合預(yù)測(cè)����,因此優(yōu)于任何一個(gè)單分類的做出預(yù)測(cè)。
聚類算法
實(shí)際應(yīng)用:
用戶畫像��,廣告推薦,Data Segmentation���,搜索引擎的流量推薦���,惡意流量識(shí)別
基于位置信息的商業(yè)推送,新聞聚類��,篩選排序
圖像分割�,降維,識(shí)別�����;離群點(diǎn)檢測(cè)�;信用卡異常消費(fèi);發(fā)掘相同功能的基因片段
聚類算法:
一種典型的無監(jiān)督學(xué)習(xí)算法�,主要用于將相似的樣本自動(dòng)歸到一個(gè)類別中。
在聚類算法中根據(jù)樣本之間的相似性�,將樣本劃分到不同的類別中,對(duì)于不同的相似度計(jì)算方法��,會(huì)得到不同的聚類結(jié)果�,常用的相似度計(jì)算方法有歐式距離法。
人工智能之機(jī)器學(xué)習(xí)教程[黑馬程序員]
認(rèn)識(shí)聚類算法【機(jī)器學(xué)習(xí)必學(xué)】
meanshift算法通俗講解【meanshift實(shí)例展示】
黑馬程序員ai人工智能課程




文章封面圖.png) javaee
javaee科列表頁(yè)面右側(cè)廣告圖.jpg) python大數(shù)據(jù)
python大數(shù)據(jù) web
web科列表頁(yè)面右側(cè)廣告圖230x148.jpg) ui
ui據(jù)學(xué)科列表頁(yè)右側(cè).png) cloud
cloud科列表頁(yè)面右側(cè)廣告圖.jpg) test
test c
c netmarket
netmarket pm
pm Linux
Linux movies
movies robot
robot uids
uids AI
AI.jpg) jdbc
jdbc











 AI智能應(yīng)用開發(fā)
AI智能應(yīng)用開發(fā) AI大模型開發(fā)
AI大模型開發(fā) AI鴻蒙開發(fā)
AI鴻蒙開發(fā) AI嵌入式+
AI嵌入式+ AI大數(shù)據(jù)開發(fā)
AI大數(shù)據(jù)開發(fā) AI運(yùn)維
AI運(yùn)維 AI測(cè)試
AI測(cè)試 跨境電商運(yùn)營(yíng)
跨境電商運(yùn)營(yíng) AI設(shè)計(jì)
AI設(shè)計(jì) AI+短視頻直播運(yùn)營(yíng)
AI+短視頻直播運(yùn)營(yíng)


